

If you use video for traffic monitoring, security cameras, retail loss prevention—any “video everywhere” deployment—you’re likely pushing video streams into edge nodes and leaving the videos scattered across buckets and blob stores. On those same edge nodes you’re also running, or wanting to run, edge AI—detecting and tracking objects, estimating speed and direction, mapping activity to zones/lanes/doors, and stamping every frame with time, camera, and location context. But the moment someone asks, “show me the footage,” your system collapses into routing logic and bucket hunting. And when the next question is, “show me the clip where object X was between time range Y to Z,” you scramble—iterating over clip after clip until you stumble onto the right one.
This problem is a missing logical layer: you’ve built storage, but not a system. You have blobs without an index, clips without a catalog, and—despite edge AI—your detections, tracks, and geofenced events aren’t cleanly tied back to the exact video segments they came from. So every investigation becomes a manual scavenger hunt across distributed infrastructure and contextless repositories.
Most companies try to “fix” this by hauling everything into one central store. It can work… briefly. Then bandwidth caps hit, latency spikes, egress fees pile up, and the operational burden becomes a permanent tax. Worse, pushing all video upstream prevents real-time workflows, eliminates data privacy and sovereignty, and turns your architecture into a single point of failure: when the central pipeline goes dark, visibility goes with it.
The deeper issue is that most teams default to a follower mindset: they adopt solutions prescribed by cloud providers without questioning the incentives. The “centralize everything” playbook isn’t neutral—it’s optimized for the provider’s economics, not yours.
The solution is to do the exact opposite of the status quo: manage the video files, inference, and context at the edge or as close to where that data is generated. Data stays in place—you don’t backhaul terabytes “just in case.” Across the network, you send only two things: the request and the minimum data required to answer it. When someone asks, “show me the clip where object X was between Y and Z,” you query the logical intelligence layer, resolve the exact clip(s), and stream only what’s needed.
SQL-embedded access to distributed video blobs
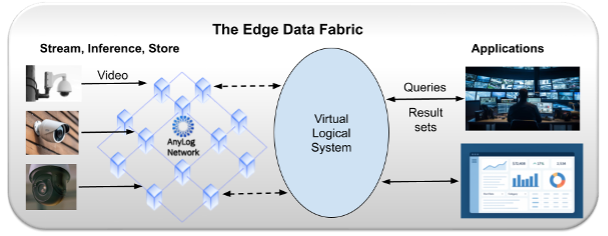
AnyLog is containerized software that, when deployed on edge nodes, creates a logical data layer spanning every node—so you can execute queries and extract intelligence as if the data is stored in a single database. AnyLog is database-agnostic by design: it connects to and virtualizes multiple database and storage backends at once, so you can mix and match SQL databases, document stores, and object/blob storage without rewriting application logic. We call this an Edge Data Fabric. Instead of centralizing data (telemetry, video, blobs), AnyLog lets you treat distributed datastores as one logical system: you send only queries across the network, execute where the data lives, and pull back only the results you actually need.
The value proposition is efficiency and simplicity: only the data you need moves across the network, and you never have to know the topology or ontology of the network or data. AnyLog’s query protocol is backed by decentralized metadata—powered by a blockchain (or AnyLog’s blockchain emulator)—that maintains the routing and resolution facts required to answer a request: which node(s) hold the relevant data, how to reach them, and how to retrieve exactly what was asked for.
Why the blockchain? Because it’s the opposite approach everyone else takes; and it’s much simpler.
Most systems centralize metadata behind a custom service: a database, an API tier, caches, failover logic, access control, monitoring… and suddenly your “metadata layer” is its own product with its own outages. Instead, each AnyLog node independently synchronizes with an autonomously operating blockchain that nodes can write and read network-related metadata, so there’s no bespoke metadata service to build, scale, or debug.
By using a blockchain, the metadata remains highly available, consistent, and auditable by default. Every AnyLog node can query any blockchain node for the latest metadata updates: metadata access doesn’t hinge on one region, one database, or one “control plane” endpoint.
A Napster-like solution for video streaming and real-time AI
AnyLog’s solution for managing video is simple—and intentionally so.
Stream RTSP feeds to any AnyLog node. AnyLog automatically captures each stream into time-aligned clips (1-minute increments by default) and stores them in place within localized blob datastores.
To enable AI, you expose your model over gRPC—running on the same edge node or a nearby node—then provide AnyLog with the gRPC endpoint. AnyLog automatically invokes the model on each frame, handling the frame delivery, scheduling, and continuous execution without a separate inference pipeline.
Inference results are pushed directly into a SQL database as structured rows: timestamps, camera IDs, object classes, confidences, tracks, zones, and any model-specific attributes the model emits. Now videos become searchable with context-rich SQL—not just “find a file,” but “find the moment something happened.”
And because AnyLog maintains the metadata that links every SQL row back to the exact underlying clip(s), your SQL queries don’t stop at a pointer. The same query context can dynamically retrieve and stream the corresponding video clips—immediately—without needing to know which edge node stored them.
Those clips stream directly into AnyLog’s GUI or any browser. You can review evidence on demand including playback, or use AnyLog’s GUI as a real-time monitoring dashboard to watch individual feeds live or view many camera livestreams at once—while AnyLog continues clipping, indexing, and executing inference in the background at the edge.
AnyLog is the Napster for edge data and video: video and telemetry stay where they are generated, but applications and users get a single logical way to discover, resolve, and retrieve exactly the data they need on demand. Deploy an AnyLog software container on each edge node and you instantly get an Edge Data Fabric that routes queries to the right place, streams the right clips, and moves only the minimum required data across the network.
{kind=link}